UNASSIGNED恢复
查看所有未分配的分片
curl http://172.31.50.119:9200/_cat/shards?v | grep UNASSIGNED
查看未分配的分片报错信息
curl -XGET 10.241.241.101:9200/_cluster/allocation/explain?pretty
查看分片恢复进度
curl -XGET 172.31.50.119:9200/{index_name}/_recovery?active_only=true
情况一:failed to obtain in-memory shard lock
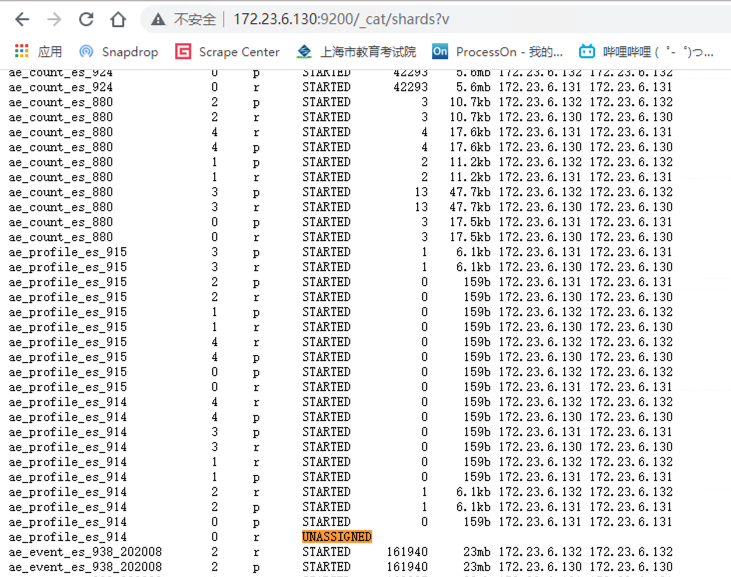
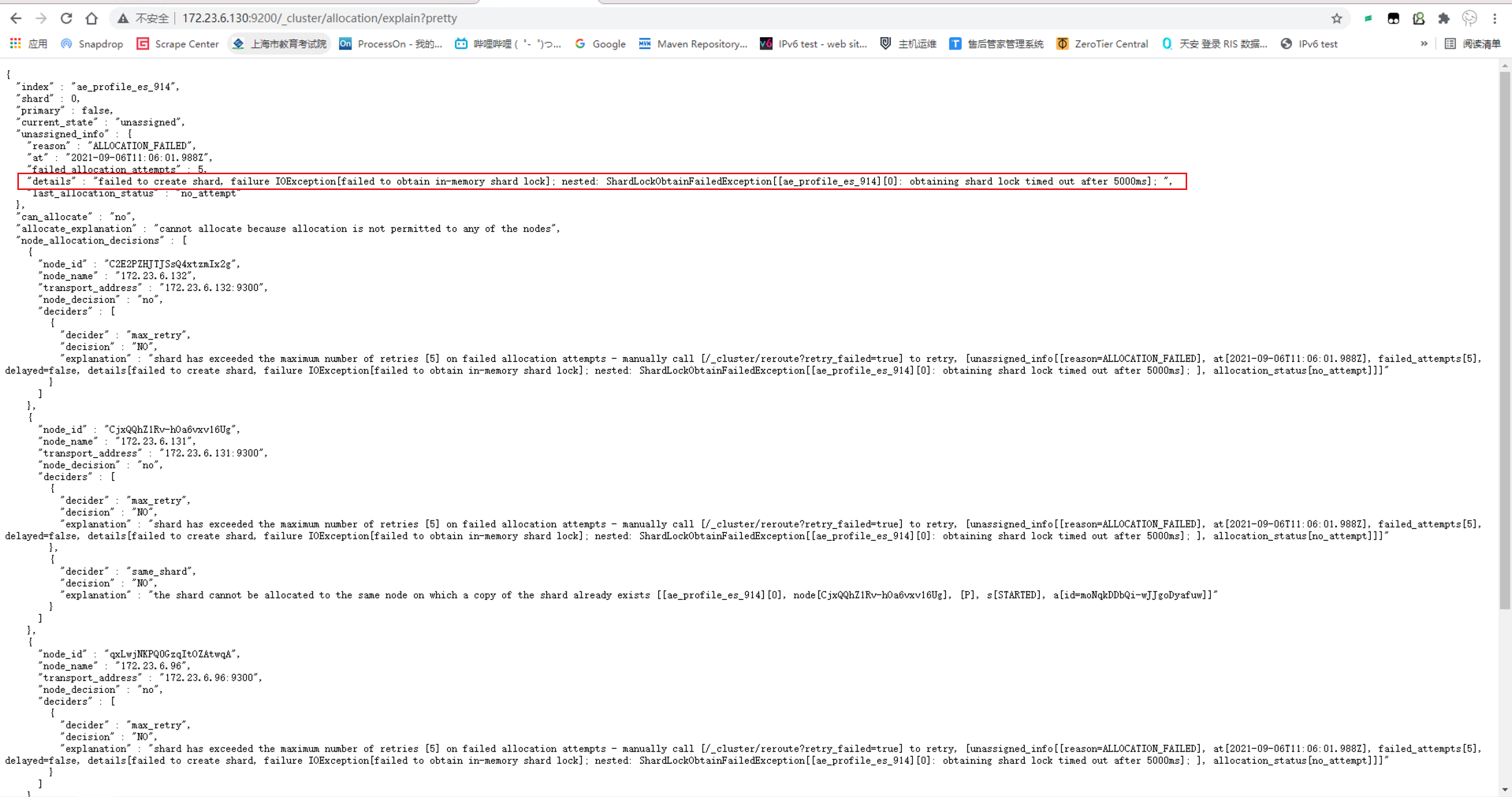
ES集群中,部分索引分片分配失败。报错如下:
failed shard on node [OYWGaeq_RWiYnQgj]: failed to create shard, failure IOException[failed to obtain in-memory shard lock]; nested: ShardLockObtainFailedException[[index_db][0]: obtaining shard lock timed out after 5000ms];
查看索引分片恢复状态
curl -XGET 10.241.241.101:9200/{index_name}/_recovery?active_only=true
curl -XGET http://172.31.50.119:9200/_cat/recovery?v
如果没有在恢复,可能是超过了最大恢复次数,可以手动再次执行恢复
处理方式,kibana中执行如下命令:
curl -XPOST '172.31.50.120:9200/_cluster/reroute?retry_failed=true'
或者手动指定(带参数)
POST /_cluster/reroute?retry_failed=true
{
"commands": [
{
"allocate_replica": {
"index": "ae_count_es_533",
"shard": 9,
"node": "es_other_data4"
}
}
]
}修改分片恢复重试次数
curl -XPUT '172.31.50.120:9200/_all/_settings?pretty' -d '{
"index.allocation.max_retries" : 10
retry_failed
(可选,布尔值)如果为true,则重试由于后续分配失败过多而阻塞的分片的分配。
附:es reroute api(官网说明)
附:常见es分配失败原因:
1)INDEX_CREATED:由于创建索引的API导致未分配。
2)CLUSTER_RECOVERED :由于完全集群恢复导致未分配。
3)INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。
4)DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。
5)NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。
6)EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。
7)REPLICA_ADDED:由于显式添加副本分片导致未分配。
8)ALLOCATION_FAILED :由于分片分配失败导致未分配。
9)NODE_LEFT :由于承载该分片的节点离开集群导致未分配。
10)REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。
11)REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。
12)REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。